Human Segmentation Network
The project consist in the implementation of a system able to process a human picture and produce as output the image segmented by body parts.
High-Level Architecture
The system is composed by:
- Machine Learning Model: component that takes care of image segmentation using Computer Vision and neural networks;
- Backend: component that allows to use services using REST APIs;
- Web-App: component that provides a simple UI for using system functionalities.
Tech choices:
- minikube as Container Orchestrator;
- Docker as Container Runtime.
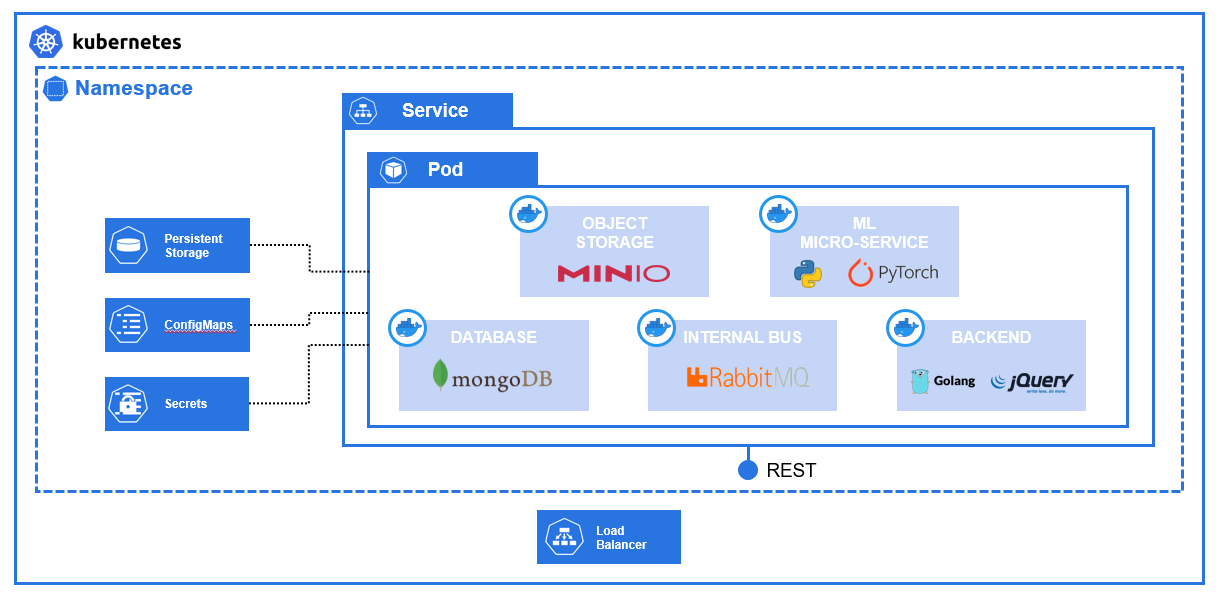
In particular, the components are the following (shown in Figure 1):
- Web-App: implemented in HTML-CSS-Bootstrap-jQuery, allows an easy interaction with the system via a simple browser UI. Frontend interacts with the Backend via REST APIs.
- Backend: implemented in Golang for performance reasons, it provides REST APIs with which is possible to interact with the system.
- Data Storage: image processing requests are stored in a MongoDB where backend can track progress and completion of each task.
- Object Storage: both input raw image and output segmented image need a place to be stored, done thanks to the use of MinIO.
- Decoupling: ML micro-service requires lots of compute power, so there is a need to decoupling the backend from the model. RabbitMQ is the Message Broker chosen for this.
For sake of simplicity and speed, as per the other examples, I kept all the containers on the same Pod using a Deployment object. In a scalable deployment, the containers should be deployed on different pods obviously.
Low-Level Architecture
The system working operation can be described with four sub-sections:
- Frontend Architecture;
- Image Inference Flow;
- Results Serving Flow;
- Machine Learning Model.
Frontend Architecture
Here below there is the graphical representation on how the Frontend software is architected. Frontend then it’s served as static site by the Golang Backend.
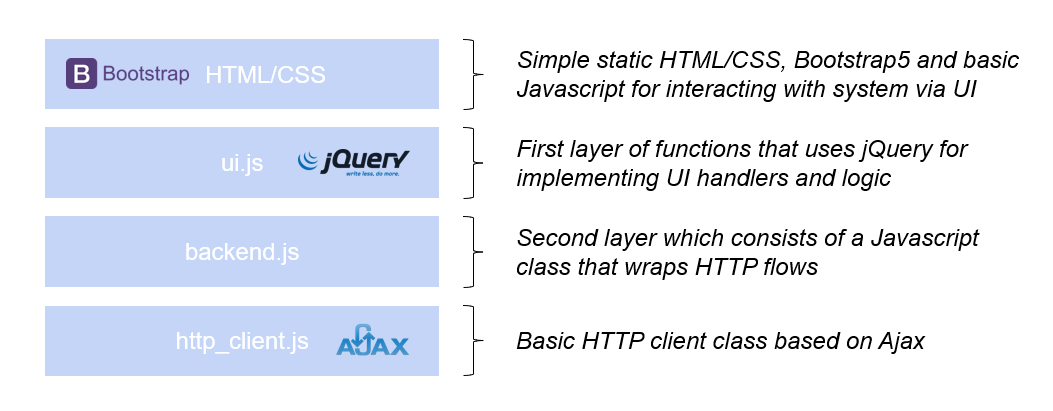
Image Inference Flow
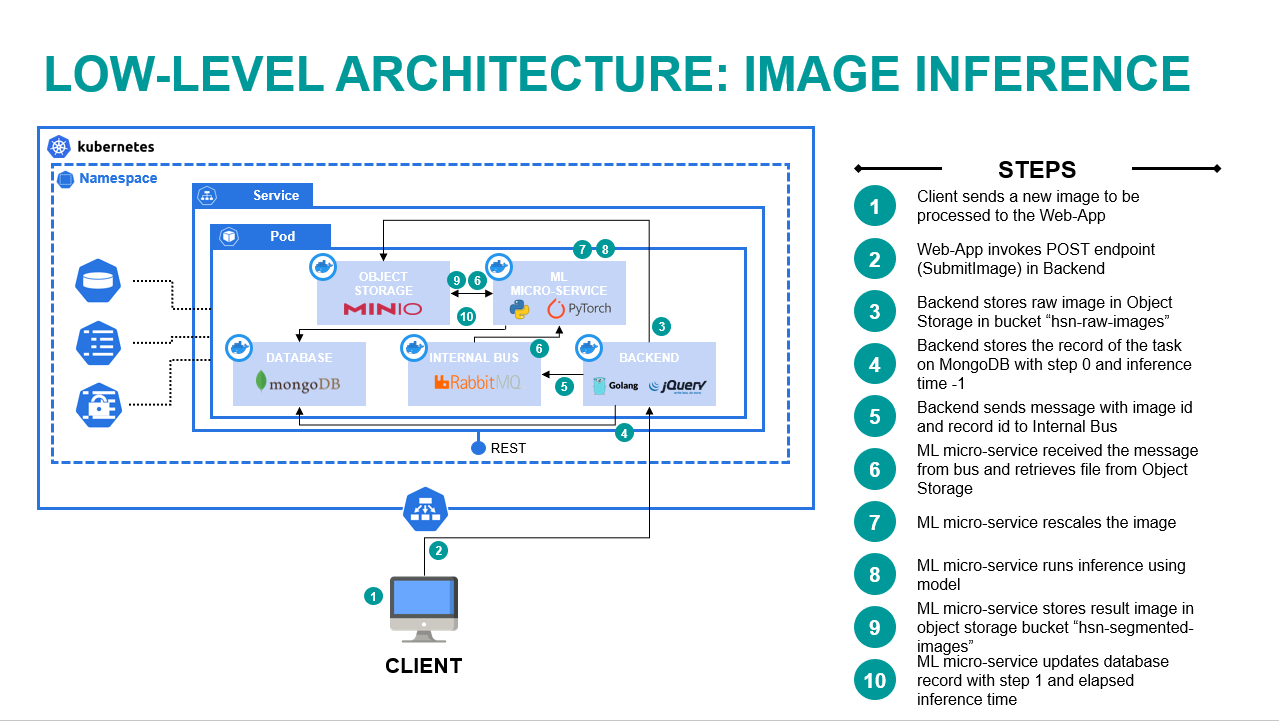
This flow is responsible for receiving a new image to process, inferencing the results and serving the resulting image to the user.
The image below describes the steps for the flow:
- User sends a new image to be processed using the Web-App.
- Web-App invokes a POST call (SubmitImage) in the REST API backend.
- Backend stores the raw image in the MinIO bucket “hsn-raw-images”.
- Backend stores the record of the task on MongoDB with step 0 and inference time set initially to -1.
- Backend sends a message to RabbitMQ with image id (i.e. MinIO object id) and MongoDB id.
- Machine Learning micro-service receives the message and retrieves the image from MinIO.
- Machine Learning micro-service rescales the image based on the maximum allowed dimension, defined in the ConfigMaps.
- Machine Learning micro-service produces the inference of the model.
- Machine Learning micro-service stores the result image in MinIO bucket “hsn-segmented-images”.
- Machine Learning micro-service updates the MongoDB record with step 1 and the elapsed inference time.
Results Serving Flow
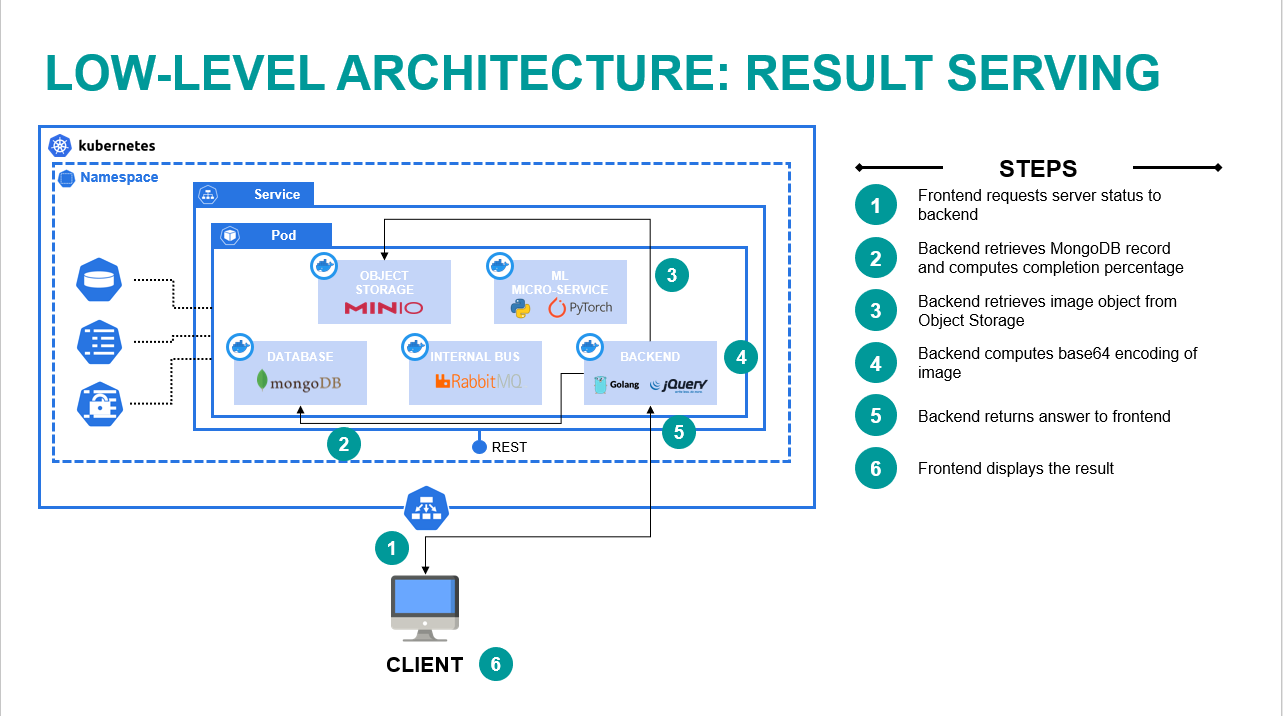
This flow is responsible for providing to the user the status of the server and the final result of the inference.
The image below describes the steps for the flow:
- Frontend requests server status to backend passing the image id, i.e. identifier of the task.
- Backend retrieves the MongoDB record and computes the percentage of completion.
- Backend retrieves the image object from MinIO.
- Backend computes the base64 encoding of the image.
- Backend returns the answer to the frontend.
- Frontend displays the results to the user.
Machine Learning Model
The goal of the Machine Learning model is to receive as input a raw image and to present as output the pixel-wise segmentation of it based on body parts.
Initially, I proceeded with some research on the internet to evaluate what was available. All the considered models used publicly available datasets, like PASCAL, CIHP, MHP, ATR, etc.
Deeplab v3 Plus
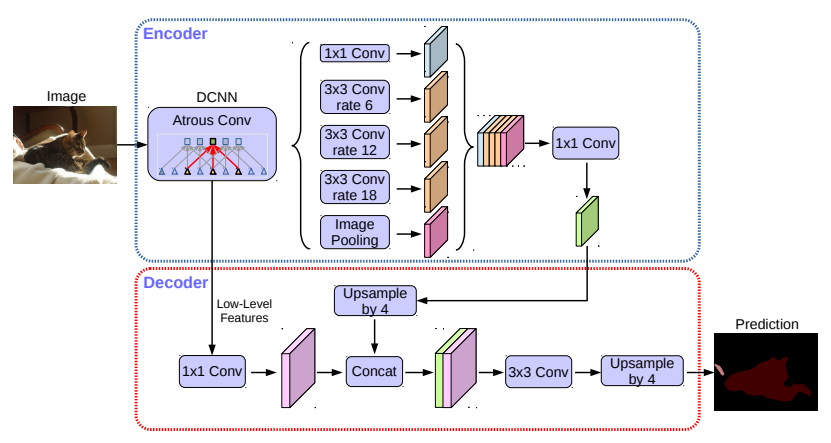
One of the most interesting model was Deeplab v3 Plus (article here) from Google, whose architecture is visible in Figure 5.
The network uses as Dense Convolutional Neural Network the well-known Xception module, still by Google (article here). Here below the architecture of the Xception block with Depth-wise Separable Convolution.
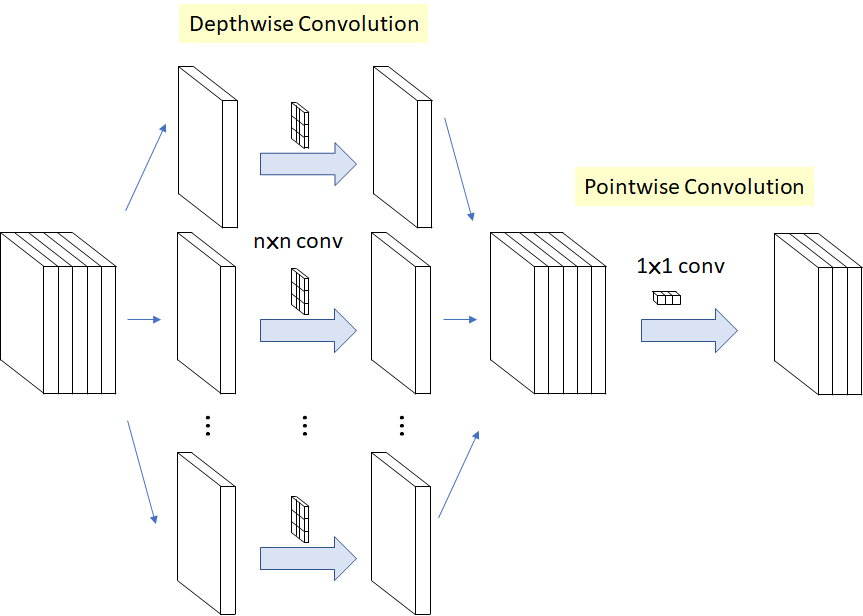
While the results of Deeplab v3 Plus are very promising on PASCAL dataset (Figure 7), with up to 78.3% accuracy with ResNet101, the application of it on only the Person part of the PASCAL dataset was not satisfying.

Graphonomy
While Deeplab v3 Plus had already achieved good results with PASCAL dataset, especially with ResNet 101, the authors of Graphonomy neural network (article here) realised that there was space for improvement by allowing some reasoning. The Deeplab v3 Plus neural network, so far, was in fact always trained on a single dataset (e.g. PASCAL in the example of Figure 7).
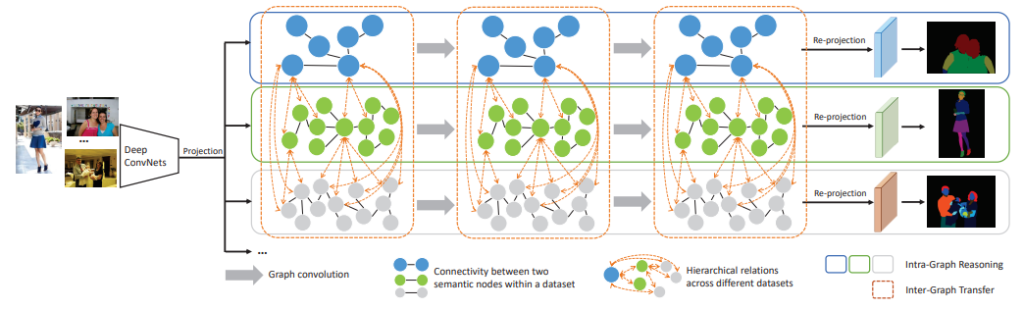
The improvement could be achieved by allowing the network to reason on the results coming from different datasets at the same time:
PASCAL Person Part: pixel-wise annotation of images into 6 categories of human body parts (head, torso, upper arm, lower arm, upper leg, lower leg); ATR: pixel-wise annotation of images into 18 categories related to both clothing and human body (face, sunglasses, hat, scarf, hair, upper cloth, left arm, right arm, belt, pants, left leg, right leg, skirt, left shoe, right shoe, bag and dress); CIHP: pixel-wise annotation of images into 19 categories related to both clothing and human body (face, upper clothes, hair, right arm, pants, left arm, right shoe, left shoe, hat, coat, right leg, left leg, gloves, socks, sunglasses, dress, skirt, jumpsuit, scarf). The network is able then to reason (intra-graph and inter-graph) on the recognised human body and clothing objects, making the inference accurate. For example, if a hat is recognised, then it’s likely that nearby there could be a head or hair.
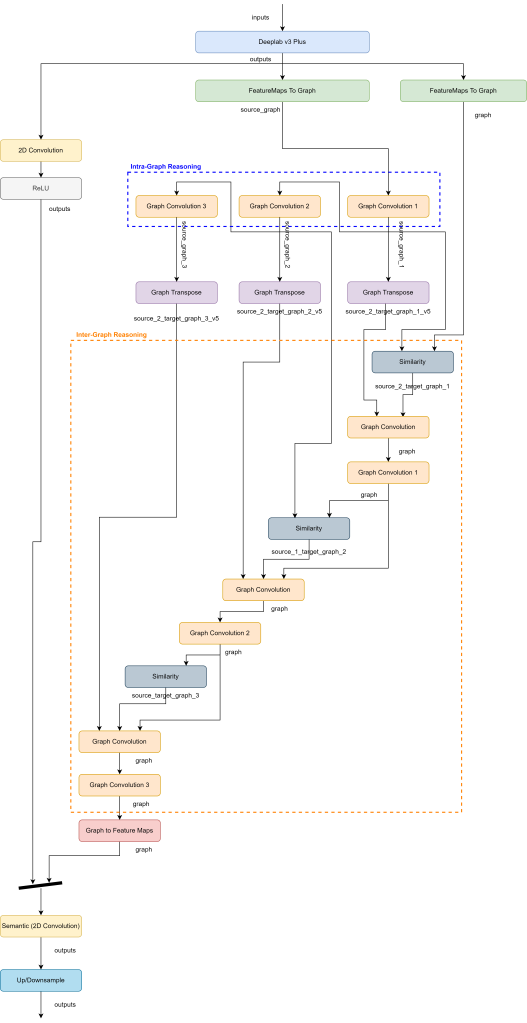
See in the images below the architecture concept and the Neural Network detailed architecture.
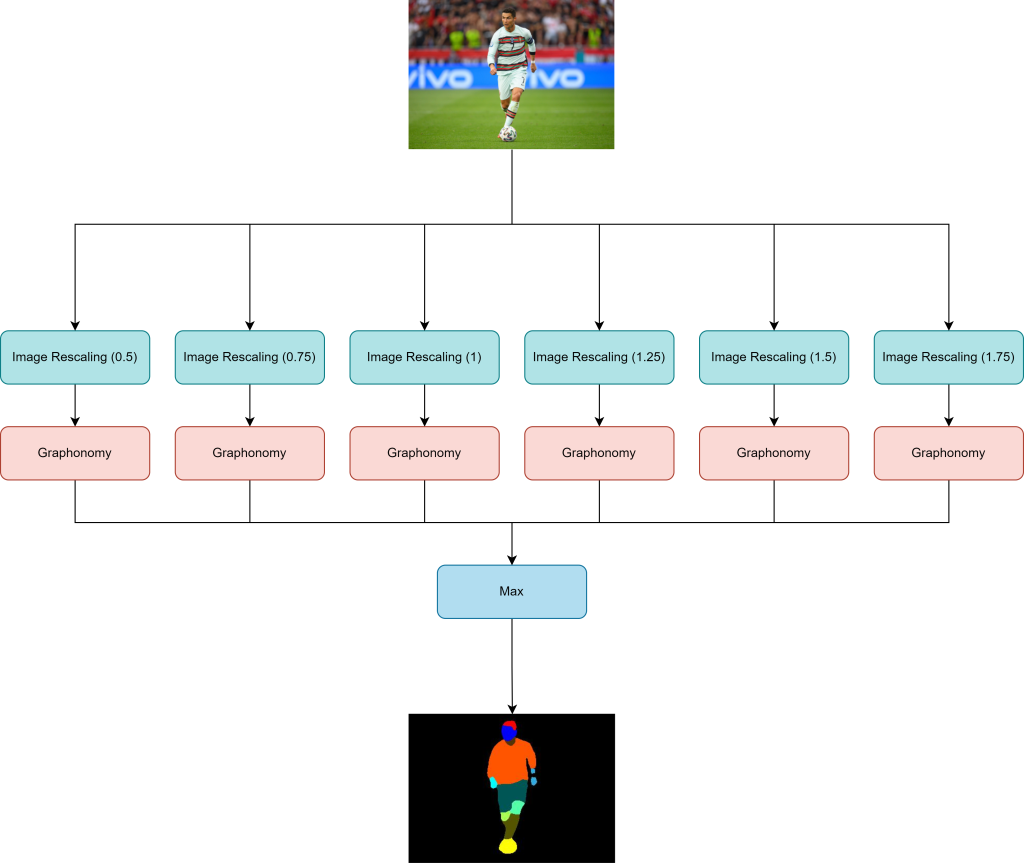
Lastly, the network is run multiple times with different resizing ratios in order to increase accuracy. Only the most confident partial result is taken out and presented as inference result. See in the image below the graphical representation of it.
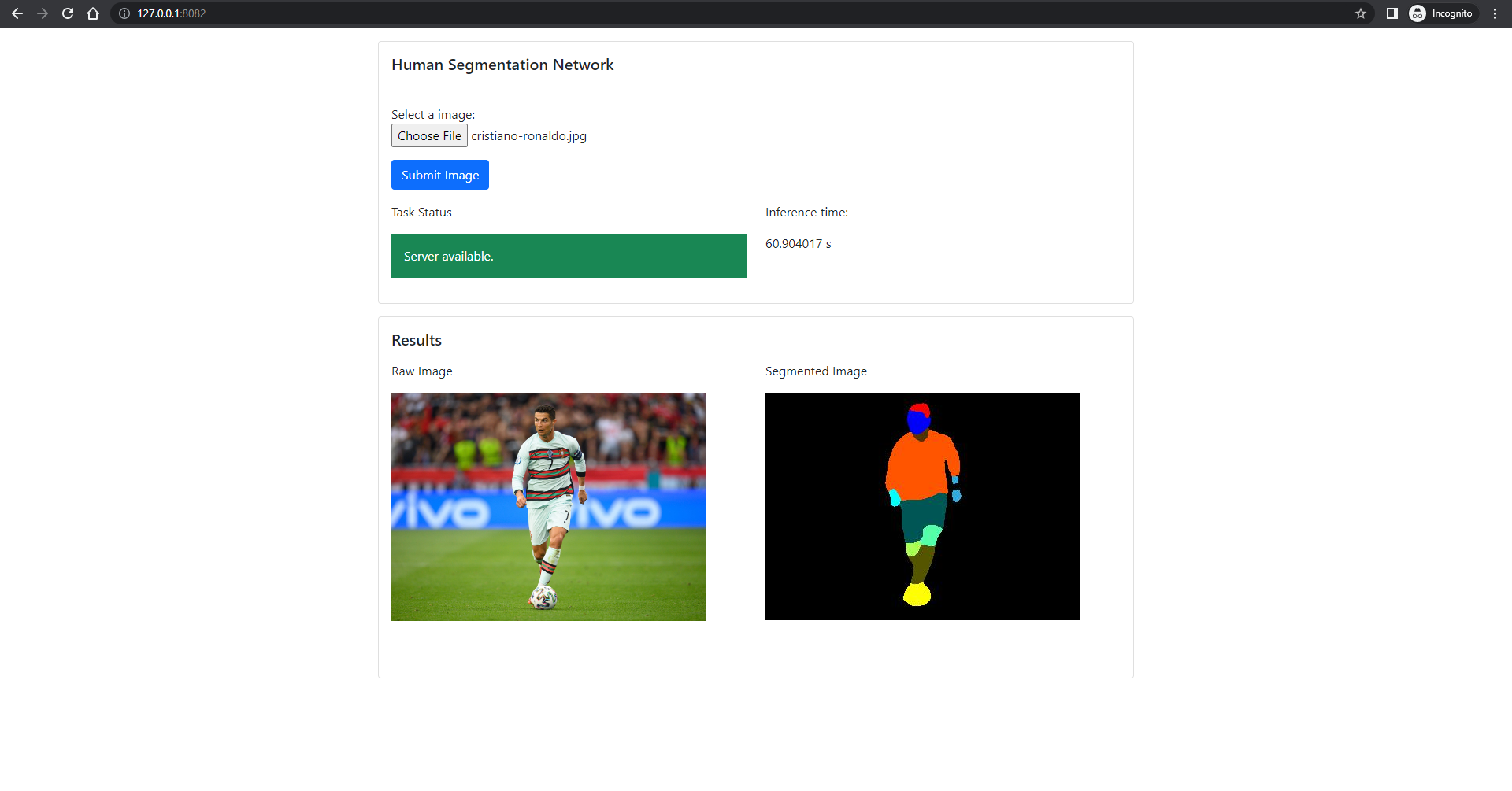
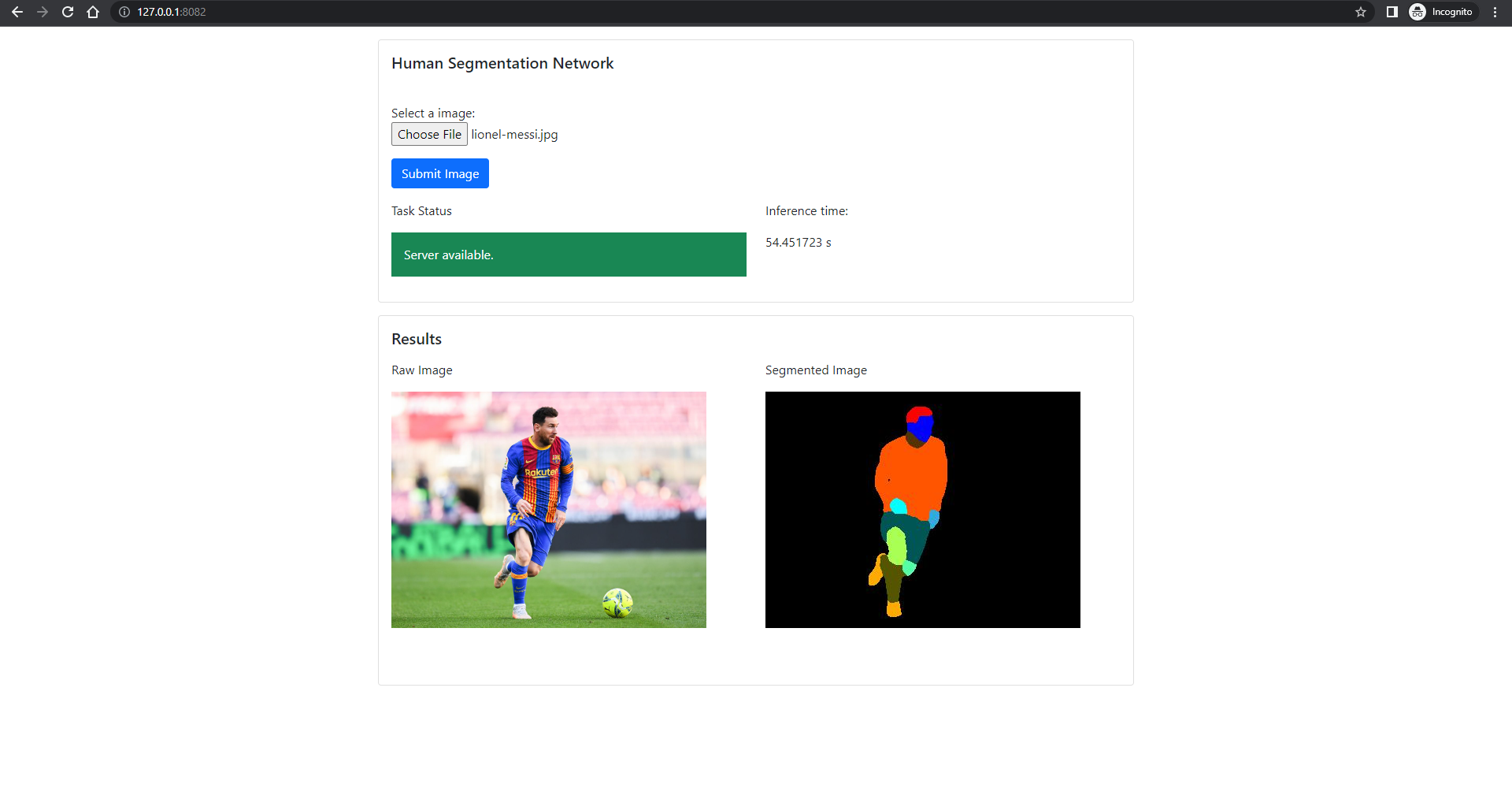
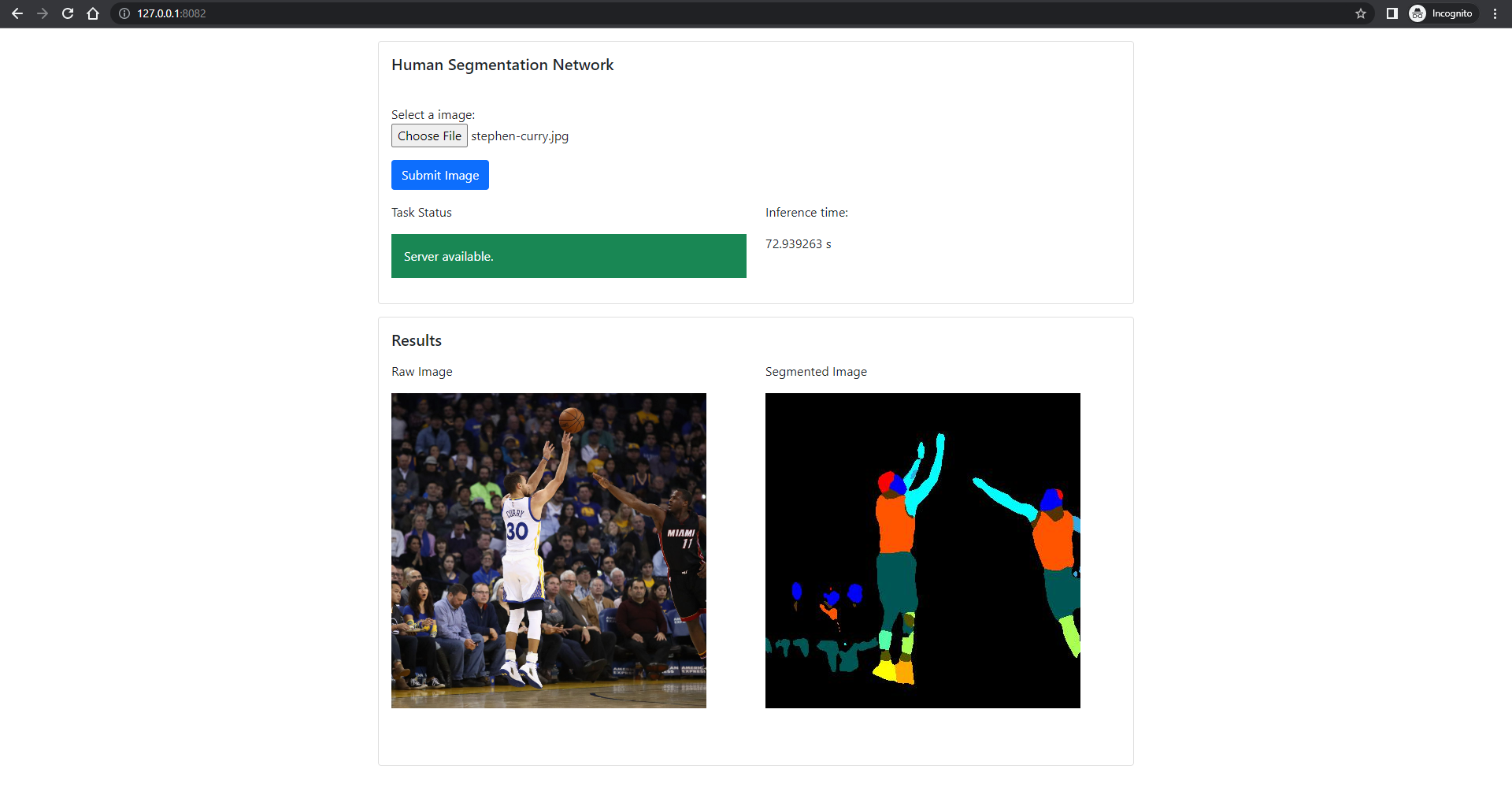
Results
In this section there are the results of the project, in terms of screenshots of the frontend and a brief video that shows the working operation. The computer on which the inference was run does not ave a GPU, hence the slowness of the inference.